Scraping Meta Tags For Social Media With Kotlin
While working on Tactycs, my marketing software startup, we needed functionality to pull metadata in the same way that the major social platforms do. This information is then used to show realistic previews of what our user's social posts will look like once submitted to each platform.
For example, here is a post preview for LinkedIn that links to another post of mine discussing cofounders inside the Tactycs software.
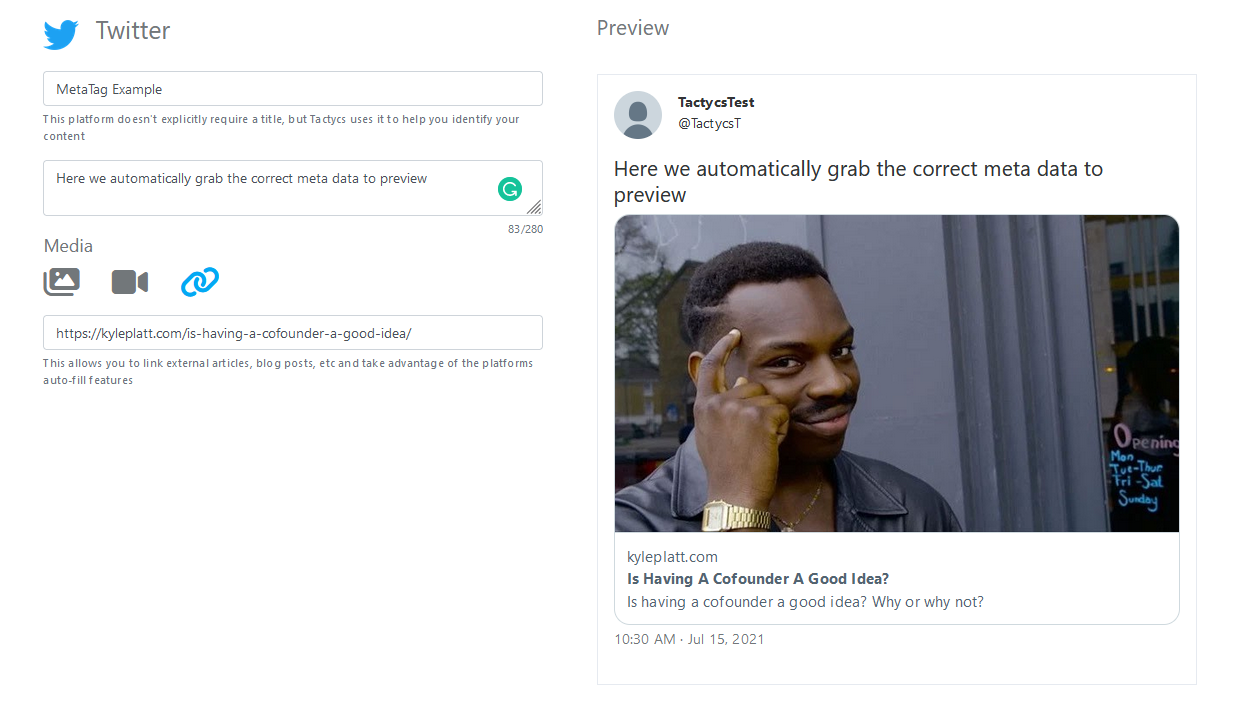
Here is what a post looks like directly from Twitter that has that same link.
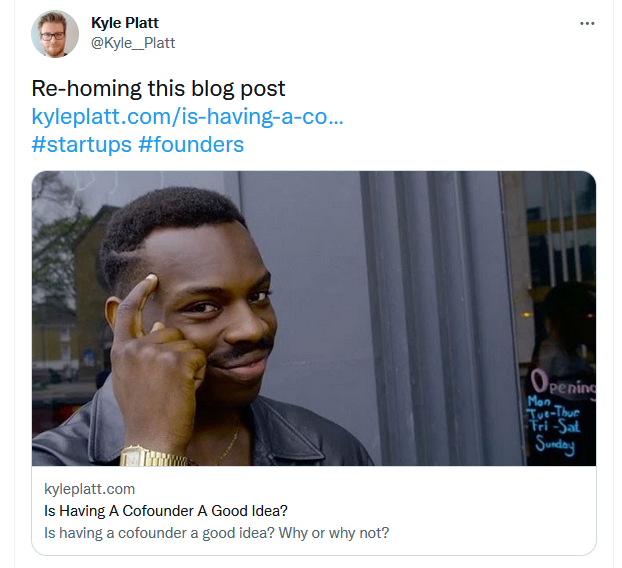
As you can see we correctly grabbed and used the metadata from the link to reproduce a social media post before it even existed.
How To Scrape Metatags Very Quickly In Kotlin
The actual implementation of the scraping was incredibly simple. The component that makes this so easy is utilizing the Kotlin focused library skrape{it}. In their words "skrape{it} is a Kotlin-based HTML/XML testing and web scraping library that can be used seamlessly in Spring-Boot, Ktor, Android or other Kotlin-JVM projects".
Note: everything here is written for skrape{it} version 1.3.0
The nice things about this library are the easy-to-use request and response handling, its automatic deserialization of HTML and XML, and then finally its built-in DSL for selecting elements.
Let's set up a simple data class to hold our results to get started.
data class MetaTags(
var ogImage: String? = null,
var ogTitle: String? = null,
var ogUrl: String? = null,
var ogDescription: String? = null,
var twitterImage: String? = null,
var twitterTitle: String? = null,
var twitterDescription: String? = null,
var twitterUrl: String? = null
)Before you yell at me, skrape{it} works by constructing your data class with no parameters and then altering them one by one. Because of this, we need to start these as vars and have all of them default to something. We can make this safer shortly.
Now lets setup the actual request and scraping functionality.
class MetaTagScraper {
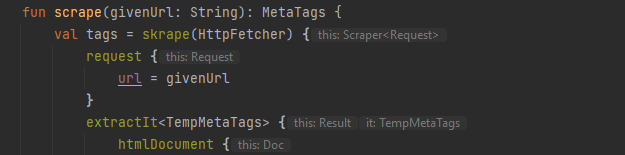
fun scrape(givenUrl: String): MetaTags {
return skrape(HttpFetcher) {
request {
url = givenUrl
}
extractIt<MetaTags> {
}
}
}
}This is the basic structure of making a get request to a URL and then beginning the scraping process. The full skrape request can serialize into data objects that we specify so we leverage that immediately with our data class. The first thing to note is the use of HttpFetcher, this is a simple, skrape provided, implementation of noscript page loading. There are other more detailed fetchers described on their website.
Inside the skrape request there are two important halves to look.
The request half. This is where we provide data on making a request to the page we want to scrape. You can give it all kinds of information such as headers, userAgent, cookies etc. But in most cases you are good to go with just providing the URL. If you are curious about what the request returns you can add a response section and play around with that.
The second half is a shortcut to the response section and jumps us straight to having parsed HTML that we can operate on. This is the extractIt<*> portion. All of the parsing logic can be handled here. Since we are only grabbing 8 pieces of data we can do this all in place.
Scraping
What we are looking for on a page looks something like this, which can be found in the header of pages with properly set up SEO.
<meta property="og:title" content="Is Having A Cofounder A Good Idea?">
<meta property="og:description" content="Is having a cofounder a good idea? Why or why not?">
<meta property="og:url" content="https://kyleplatt.com/is-having-a-cofounder-a-good-idea/">
<meta property="og:image" content="https://kyleplatt.com/content/images/2022/11/Thinking-1.png">
<meta name="twitter:title" content="Is Having A Cofounder A Good Idea?">
<meta name="twitter:description" content="Is having a cofounder a good idea? Why or why not?">
<meta name="twitter:url" content="https://kyleplatt.com/is-having-a-cofounder-a-good-idea/">
<meta name="twitter:image" content="https://kyleplatt.com/content/images/2022/11/Thinking.png">Grab that using our scraper.
extractIt<MetaTags> {
htmlDocument {
relaxed = true
it.ogTitle = meta {
withAttribute = "property" to "og:title"
findFirst {
attribute("content")
}
}
}
}Let's break this first one down quickly before adding the others.
relaxed means we don't throw an exception when an element is not found. For metatag scraping, this absolutely needs to be true as some site owners may not be settings these tags.
We are looking for a meta tag so we use the meta DSL selector. We don't just want any meta tag though so we narrow it down to something with the attribute property set to og:title.
Finally we select the first one that matches those conditions we grab another attribute content. Instead of attribute("content") you could grab text or any other facet of the element you have selected.
Now we can add the others.
extractIt<MetaTags> {
htmlDocument {
relaxed = true
it.ogTitle = meta {
withAttribute = "property" to "og:title"
findFirst {
attribute("content")
}
}
it.ogImage = meta {
withAttribute = "property" to "og:image"
findFirst {
attribute("content")
}
}
it.ogUrl = meta {
withAttribute = "property" to "og:url"
findFirst {
attribute("content")
}
}
it.ogDescription = meta {
withAttribute = "property" to "og:description"
findFirst {
attribute("content")
}
}
it.twitterImage = meta {
withAttribute = "name" to "twitter:image"
findFirst {
attribute("content")
}
}
it.twitterTitle = meta {
withAttribute = "name" to "twitter:title"
findFirst {
attribute("content")
}
}
it.twitterDescription = meta {
withAttribute = "name" to "twitter:description"
findFirst {
attribute("content")
}
}
it.twitterUrl = meta {
withAttribute = "name" to "twitter:url"
findFirst {
attribute("content")
}
}
}
}Great, now that we get all the data we need, let's combine everything and add some proper Kotlin safety into the mix.
Here is a complete file
data class MetaTags(
val ogImage: String?, //still need nullability as its possible a site has none of these tags
val ogTitle: String?,
val ogUrl: String?,
val ogDescription: String?,
val twitterImage: String?,
val twitterTitle: String?,
val twitterDescription: String?,
val twitterUrl: String?
)
class MetaTagScraper {
protected data class TempMetaTags(
var ogImage: String? = null,
var ogTitle: String? = null,
var ogUrl: String? = null,
var ogDescription: String? = null,
var twitterImage: String? = null,
var twitterTitle: String? = null,
var twitterDescription: String? = null,
var twitterUrl: String? = null
)
fun scrape(givenUrl: String): MetaTags {
val tags = skrape(HttpFetcher) {
request {
url = givenUrl
}
extractIt<TempMetaTags> {
htmlDocument {
relaxed = true
it.ogTitle = meta {
withAttribute = "property" to "og:title"
findFirst {
attribute("content")
}
}
it.ogImage = meta {
withAttribute = "property" to "og:image"
findFirst {
attribute("content")
}
}
it.ogUrl = meta {
withAttribute = "property" to "og:url"
findFirst {
attribute("content")
}
}
it.ogDescription = meta {
withAttribute = "property" to "og:description"
findFirst {
attribute("content")
}
}
it.twitterImage = meta {
withAttribute = "name" to "twitter:image"
findFirst {
attribute("content")
}
}
it.twitterTitle = meta {
withAttribute = "name" to "twitter:title"
findFirst {
attribute("content")
}
}
it.twitterDescription = meta {
withAttribute = "name" to "twitter:description"
findFirst {
attribute("content")
}
}
it.twitterUrl = meta {
withAttribute = "name" to "twitter:url"
findFirst {
attribute("content")
}
}
}
}
return MetaTags(
tags.ogImage, tags.ogTitle, tags.ogUrl, tags.ogDescription,
tags.twitterImage, tags.twitterTitle, tags.twitterDescription,
tags.twitterUrl
)
}
}Hopefully, you find this useful!